3. Infrastructures externalisées pour l’administration
Architecture de projets LLM
Dans la plupart des cas, un projet d’IA générative ne se limite pas au déploiement d’un LLM. Souvent, le projet nécessitera la présence d’une interface utilisateur, et parfois même d’une architecture RAG.
Les différents élements du développement d’une application d’IA générative sont donnés dans le rapport de l’ANSSI sur l’IA générative :
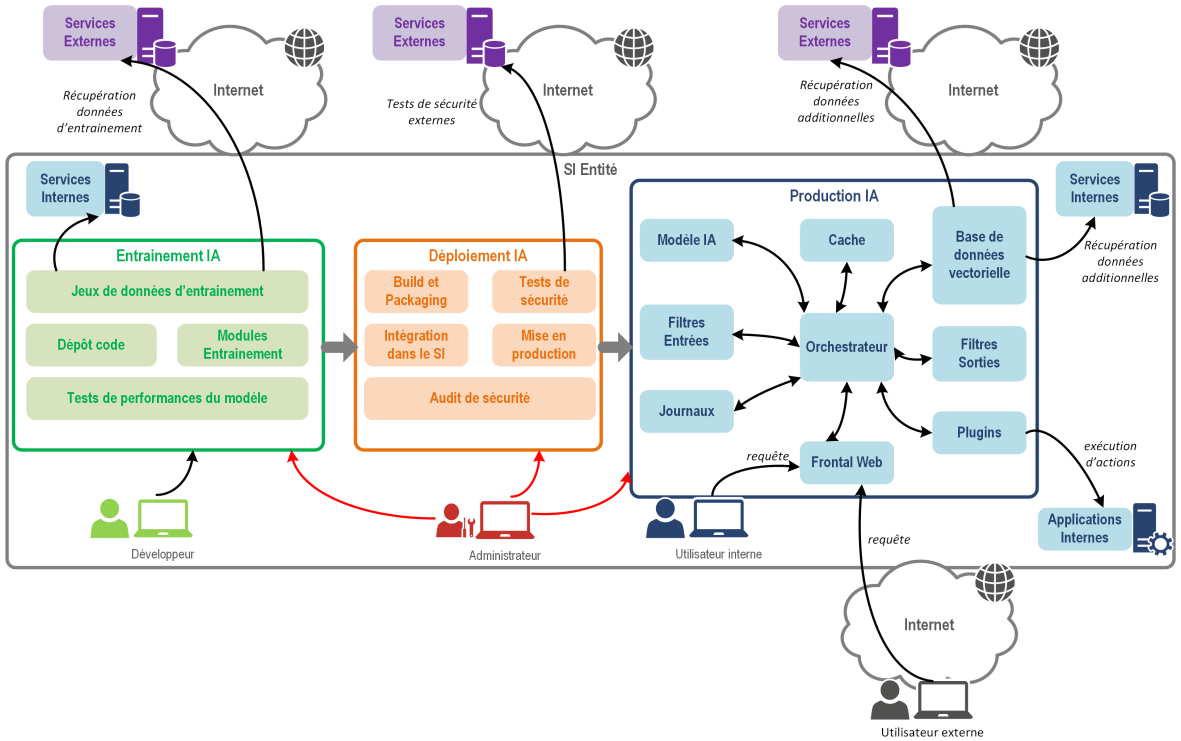
Pour le déploiement, les principales briques peuvent se décomposent en 3 grandes familles :
Service LLM
Le service LLM est la brique qui permet de faire tourner un modèle de language. Il peut être déployé sur une infrastructure en propre, ou externalisé.
Infrastructure d’inférence à base de GPU
Dans le cas où il est possible d’avoir accès à des GPUs, il existe de nombreux outils pour déployer des LLMs sur sa propre infrastructure. Ces outils permettent de déployer à de multiples échelles des modèles LLM libres.
Cette option est détaillée dans les parties Service LLM avancé et Service LLM à grande échelle.
API
Cette option présente l’intérêt d’être prête à l’emploi et de ne pas nécessiter de posséder infrastructure dédiée.
- API Albert : Offre fournie par la DINUM pour les administrations.
- Externe non sécurisée : Ces solutions sont envisageables où les besoins en performance sont importants et les contraintes de sécurité sont faibles. Voici quelques exemples de solutions :
Ollama
ollama permet le déploiement en local de nombreux modèles d’IA générative (LLM, multimodal LLM, embedings, Code completion, …), à l’aide d’une unique ligne de commande :
ollama run llama3.2Pour permettre l’exécution dans le plus de contexte possible, ollama donne le choix de la taille du modèle et du niveau de quantization.
ollama run gemma2:27b-instruct-q2_Kollama n’est pas adapté dans les cas où le projet a des contraintes de performance et/ou doit gérer les requêtes simultanées de plusieurs utilisateurs.
Gestion d’une base de connaissance
Dans le cas où le projet nécessite l’utilisation de Retrieval Augmented Generation (RAG), il est nécessaire de mettre en place une infrastructure permettant de stocker et de récupérer les données nécessaires au modèle.
Les architectures RAG se concentrent principalement autour d’une base de données vectorielles (cf Benchmark des différentes bases vectorielles.
Un exemple d’infrastructure pour un projet RAG est donné dans le cadre du projet CARADOC (cf. déploiement CARADOC):

Interface utilisateur
L’interface utilisateur est la brique qui permet à l’utilisateur d’interagir avec le modèle et/ou les résultats du modèle. Elle peut être développée spécifiquement pour le projet, ou utiliser un outil existant.
Pour des applications simples, streamlit et Gradio propose des interfaces de chat. Un exemple d’outil développé et déployé avec Gradio est Compar:IA.
Dans les cas où les intéractions sont plus complexes, il peut être nécessaire de passer sur une application plus lourde. Des exemples d’applications sont abordées dans la partie Déploiement d’applications.
Pistes d’infrastructure
Dans beaucoup de cas l’accès à des GPUs est un des principaux freins à l’expérimentaion et la mise en production d’un cas d’usage d’IA générative. L’acquisition d’un cluster GPUs n’est pas toujours une possibilité pour des questions budgétaires ou techniques. Cependant, plusieurs alternatives sont envisageables (ou en cours de construction) par les administrations pour externaliser cette infrastructure.
Dans ce cadre, les principales variables à prendre en compte sont les contraintes de sécurité de l’application. Cette question va à la fois déterminer les solutions accessibles et imposer des choix architecturaux.
2 principales solutions d’externalisation sont possibles :
Dans certains cas, il peut être intéressant de mettre en place une architecture hybride Cloud + API d’inférence. Ce qui permet de bénéficier de l’agilité de développement des solutions Cloud, tout en réduisant les coûts relatifs à l’approvisionnement de GPUs.
Cloud Public
SSP Cloud : A ce jour, le SSP Cloud via sa plateforme ONYXIA (hébergée et dévelopée par l’INSEE), est la principale plateforme publique mettant à disposition des GPUs à ses utilisateurs. Les ressources sont cependant très limitées et la plateforme est plus orientée autour du développement de projet que de la mise en production. cf Déploiement d’un LLM sur SSP Cloud
Cloud pi : Cloud PI est le cloud du ministère de l’intérieur, il ne semble pas proposer à date de provisionnement de GPUs. Il fournit cependant une offre IAAS (Infrastructure As A Service) et PAAS (Platform As A Service) pour l’hébergement d’applications.
Nubo : Nubo est le service cloud du ministère de l’économie et des finances, qui propose un service IAAS. Via sa solution Nubonyxia, il est possible d’intéragir avec l’interface Onyxia et le service Kubernetes sous jacents. Nubo ne propose pas à date de provisionnement de GPUs.
Pour définition de ce que recouvre les offres de service PAAS et IAAS, se référer à ce lien
Cloud externe
La qualificiation SecNumCloud a été mis en place par l’ANSSI pour assurer des normes de sécurité aux utilisateurs de produits cloud. A ce jour, peu d’entreprises ont acquis cette qualification. Voici quelques exemples de fournisseurs :
- Dassault - Outscale IAAS avec accès GPU
- Thales - Sens (Implémentation de GCP sur une infrastructure sécurisée) PAAS
- Cloud Temple IAAS
Plus d’informations sur ce type de services sont disponibles ici.