Bonjour à tous,
Merci pour votre intérêt et participation au premier datadrink virtuel !
Nous vous proposons de revisionner le datadrink Datascience & Covid-19 ci-dessous et nous en profitons pour vous partager la première infolettre du Lab IA d’Etalab. Elle s’adresse à la communauté du Lab IA. Vous êtes aujourd’hui plus de 270 inscrits : participants aux AMI 1 et AMI 2, datascientists de l’administration, chercheurs et prestataires de l’IA pour l’administration, et agents publics intéressés par la science des données et l’IA. Nous espérons ainsi vous partager les autres actualités du Lab IA, favoriser les échanges et rencontres autour de l’usage des données pour l’administration et le partage d’expériences et d‘outils IA pour améliorer l’action publique.
Ci-dessous :
- Revisionner le datadrink #6 en ligne du jeudi 23 avril : Data science & Covid-19 et liens utiles
- Pour une IA francophone (PIAF) : proposez un cas d’usage dans l’administration
- Projets AMI 2 : Retours d’expériences sur le lancement des projets d’IA avant et pendant le confinement
- Semaine d’immersion métier au Conseil d’Etat avec Catherine Costarramone, porteur de projet d’IA (AMI 2), et Joseph Assu-Ondo, datascientist chez StarClay
- Création d’un dossier patient fictif au CHU de Bordeaux pour lancer le projet d’IA malgré la crise du Covid-19, avec Sébastien Cossin, porteur de projet d’IA (AMI 2)
- L’Atelier #2 pour les porteurs de projet AMI 2 se tiendra en ligne prochainement !
Notre sélection de ressources à visiter :
- Soutien en Python et R entre agents de l'État pendant le confinement : visitez Spyrales
- La sélection d’Etalab des sorties du mois de mars sur data.gouv.fr
- L’Open Data Barometer devient le Global Data Barometer avec beaucoup plus d’indicateurs pris en compte, tels que la collaboration autour des données ou l’utilisation des algorithme, à visiter ici.
Revisionner le premier datadrink virtuel : Data science et Covid-19
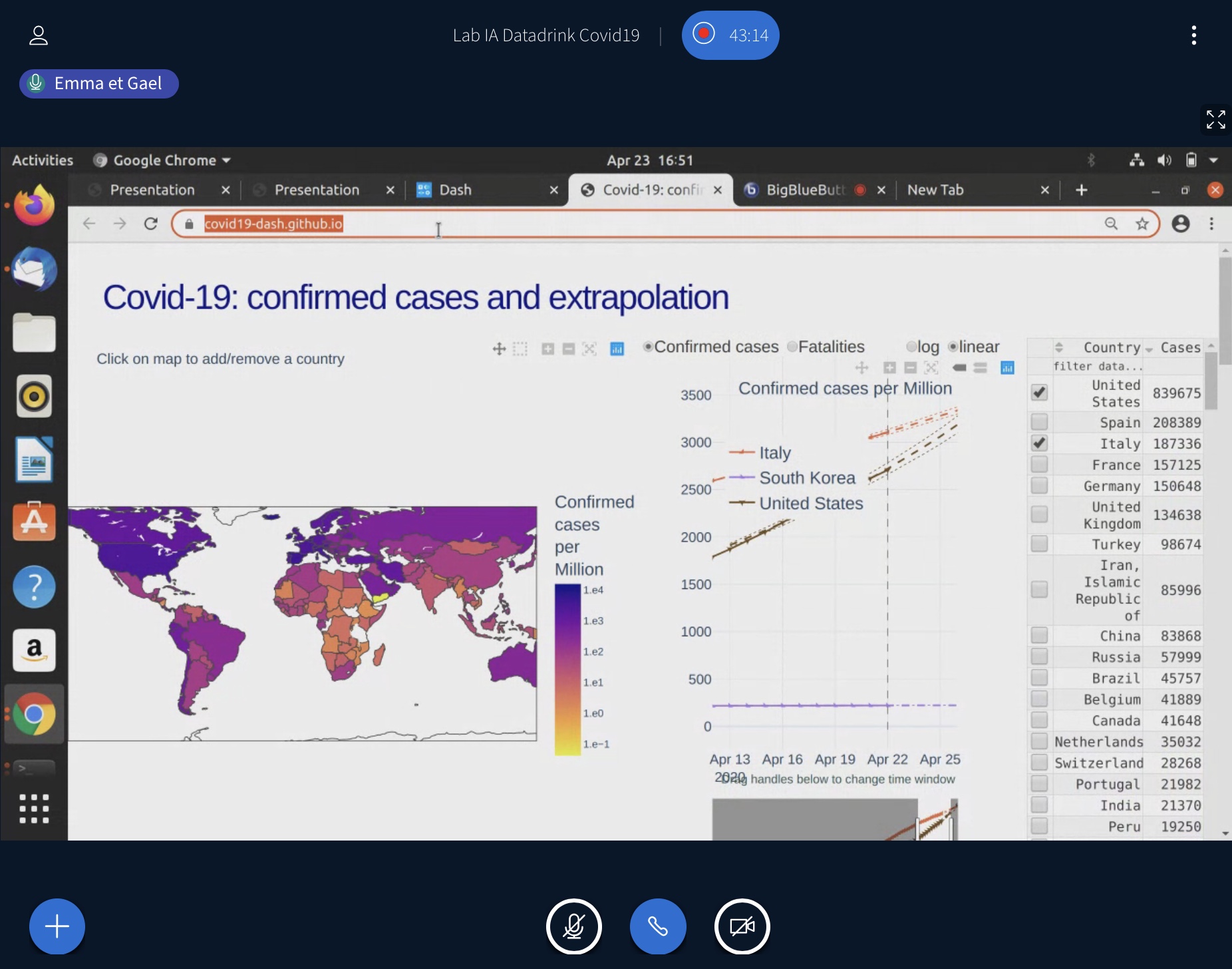
Revisionnez le datadrink en ligne
Ce jeudi 23 avril de 16h à 17h30, le Lab IA a organisé le premier datadrink virtuel sur les données pour la compréhension et modèles de prédiction de l’épidémie Covid-19: révisionnez la vidéo du datadrink #6 en ligne. Voir aussi :
Bastien Guerry (Etalab) : l’orientation médicale pour faciliter le travail du SAMU et comprendre l’épidémie. Les données seront publiées prochainement sur data.gouv.fr. Voir aussi :
- Les solutions référencées par le ministère des Solidarités et de la Santé
- La partie « arbre de décision » de l'algorithme
- Une version de démonstration du questionnaire
- Une version interactive d'une implémentation de l'algorithme
- Un outil de validation des données envoyées par les solutions implémentant l'algorithme en suivant la documentation
Rosane Ushirobira et Denis Efimov (Inria) : modèle de prédiction de l’épidémie selon différentes conditions de confinement dans six pays. Le code et les données sont disponibles sur github.
Emmanuelle Gouillart (Plotly Inc) et Gaël Varoquaux (Inria) : prédiction à court terme de l’évolution de l’épidémie dans le monde à partir de données récentes et outil de visualisation associé. Les contributions sont bienvenues pour affiner les données.
Quels indicateurs pour le déconfinement ? Appel à contribution présenté par Phong Nguyen, cellule de crise sanitaire (DREES) : une fois le confinement terminé, comment gérer les risques de nouvelles vagues de l’épidémie ? Quelles sources de données non exploitées et utiles pour prévenir la crise sanitaire? Vos suggestions ici.
Si vous avez des suggestions ou souhaitez présenter vos projets pour un prochain datadrink (10 minutes de présentation suivies de 5 minutes de questions), contactez-nous.
Pour une IA francophone (PIAF) : proposez un cas d’usage dans l’administration
 Depuis octobre dernier, 7 160 questions réponses ont été collectées par près de 500 contributeurs.
Depuis octobre dernier, 7 160 questions réponses ont été collectées par près de 500 contributeurs.Nous avons partagé les leçons de cette méthode contributive ici.
La contribution est désormais ouverte au grand public ici. Un premier jeu de données contenant 3 835 questions réponses a été publié sur data.gouv.fr.
Dans les six prochains mois, nous nous donnons pour objectif d'explorer les cas d'usage des algorithmes de questions réponses dans l'administration et nous sommes à la recherche de cas d'usage concrets. Si vous avez un projet d'agent conversationnel ou de moteur de questions réponses, n'hésitez pas à contacter l'équipe.
Voici trois exemples de cas d’usage dans l’administration Voir la plateforme Voir le code source
Projets AMI 2 - Retours d’expériences sur le lancement des projets avant et pendant le confinement
Une année pour expérimenter l’IA : après une phase de cadrage et de préparation, les projets sélectionnés par l’AMI 2 se lancent! Comment démarrer le projet de façon optimale dans les conditions actuelles ? Retour sur deux expériences de lancement : avant et pendant le confinement.
Semaine d’immersion métier au Conseil d’Etat avec Catherine Costarramone, porteur de projet d’IA (AMI 2) et Joseph Assu-Ondo, datascientist chez StarClay

Une partie de l’équipe du projet IA-JURADINFO devant les marches du Conseil d’Etat, mars 2020
Pour accueillir l’équipe StarClay, prestataire privé sélectionné pour développer les outils d’extractions d’information et d’aide à la décision pour le Conseil d’Etat, l’équipe des porteurs du projet IA-JURADINFO a organisé mi-mars deux semaines d’accueil et d’immersion métier. Catherine Costarramone, porteur du projet IA-JURADINFO au Conseil d’Etat, et Joseph Assu-Ondo, datascientist chez StarClay, nous partagent leurs retours sur cette immersion métier.
Comment avez-vous organisé ces deux semaines d’accueil et immersion métier ?
« Notre objectif était de coller autant que possible au calendrier de démarrage du projet présenté par StarClay lors de la réunion de lancement début mars : être en mesure d’accueillir physiquement l’équipe StarClay dès le lundi suivant (préparation de la salle de travail et des postes informatiques), fournir un jeu de données, et organiser un accompagnement “métier” » explique Catherine Costarramone, responsable du pilotage transverse et du suivi pour le projet.
« Ainsi, le démarrage du projet a été différé d’une (seule) journée en procédant à quelques aménagements de calendrier : à l’arrivée de StarClay, Thomas Charpentier, magistrat en charge à la Direction des Systèmes d’Information (DSI) du département de l’expertise métier des applications de la juridiction administrative, a présenté avec deux greffières de son département les rôles du Conseil d’Etat, la procédure contentieuse et les principales applications métiers (Télérecours et Skipper). Trois ateliers métier supplémentaires organisés la même semaine ont permis de rentrer dans le cœur du sujet « d’aide à la détection des séries ». Des magistrats de la Cour administrative d’appel de Paris et du tribunal administratif de Montreuil se sont déplacés pour présenter des exemples de séries et leurs critères (empiriques) pour les détecter. En parallèle, les postes de travail munis de leurs accès internet ont été préparés sous la supervision de Geoffroy Dambricourt, pilote technique du projet, par les bureaux de la DSI dédiés à cela (bureau du support aux utilisateurs du Conseil d’Etat, et bureau système réseau et téléphonie). Geoffroy a collecté les besoins en outillage de l’équipe StarClay et réalisé lui-même la configuration technique de leurs postes.
Le plus difficile fut la préparation du jeu de données, qui a demandé davantage de temps. Elle a nécessité la mobilisation de plusieurs services (internes et externes à la DSI) et donc davantage de coordination. Par ailleurs, la date de démarrage (souhaitée) du projet a été communiquée lors de la réunion de lancement. Sans être une véritable surprise, elle nous a fait prendre conscience du peu de temps à notre disposition pour préparer l’arrivée de l’équipe. Si c’était à refaire, je pense que nous aurions davantage anticipé certaines étapes de préparation, comme l’identification des critères pour constituer les jeux de données et la réservation des ressources internes pour réaliser les extractions.
Aussi, cela fait partie des aléas, Thomas [qui a soutenu et porté le projet jusqu’à sa sélection par l’Appel à Manifestation d’Intérêt] n’a pas pu participer à la réunion de lancement et a été remplacé au pied levé par David Moreau. Ce qui semblait être de mauvais augure a finalement permis de planifier dès la semaine suivante les ateliers avec les magistrats, grâce à l’appui efficace du secrétaire général adjoint. C’était la semaine juste avant le début du confinement ! »
Quelle est l’importance de cette immersion métier pour le lancement du projet d’IA ?
« Après ces rencontres, notre vision est plus claire et nous imaginons des réajustements. En effet, nous avons constaté que les briques intermédiaires sont aussi importantes que la brique finale», explique Joseph Assu-Ondo, data scientist senior chez StarClay. « En organisant ces ateliers et en mobilisant les personnes concernées, nous avons eu l’occasion de comprendre les différentes approches que les magistrats utilisent pour détecter les séries et le besoin d’analyse de connexités ou liens entre les différentes requêtes : identifier un même défendeur ou entité administrative attaquée sur plusieurs requêtes, un même requérant ou personne qui initie le recours, une même société d’avocat, un même lieu, par exemple, sont des informations qui intéressent les magistrats autant que les détections de séries.
Expérimenter, c’est aussi réorienter les axes de travail si nécessaire : cela nous demande d’ajouter une phase d’annotation, pendant laquelle les greffiers et les magistrats pourront extraire les informations pertinentes des requêtes et d’identifier les liens entre elles afin d’apprendre à l’IA à effectuer ces tâches. Bien que plus difficile à mettre en œuvre, cette phase nous garantit d’avoir de meilleurs résultats, plutôt que d’utiliser des algorithmes non supervisés qui seraient moins performants. L’analyse des connexités dans le périmètre du projet va être statué en tenant compte de la charge de travail supplémentaire qui serait nécessaire en phase de conception du schéma d’annotation (liste des connexités) et en phase d’annotation par les experts. »
Quelques infos clés sur le projet IA-JURADINFO
En juillet dernier, le projet IA-JURADINFO a été sélectionné avec 14 autres projets dans le cadre de l’Appel à Manifestation d’Intérêt (AMI) 2 pour bénéficier de l’accompagnement du Lab IA et de la DITP et développer des outils d’extraction d’information pour harmoniser la jurisprudence entre les différents échelons de l’ordre administratif et accélérer les délais de jugement.
Le réseau JURADINFO en chiffres :
- Chaque année, les 42 juridictions administratives françaises reçoivent plus de 260,000 requêtes (+7% en 2018)
- En mars 2020, 24 355 requêtes sont en attente d’être jugées, regroupées en 23 séries. Le nombre de dossiers par série est très variable, de 42 à 5 362.
- Depuis 2013, 47 000 dossiers ont été identifiés comme relevant d’une série.
JURADINFO, le système qui permet au Conseil d’Etat de centraliser et diffuser l’information sur l’existence de séries de droit parmi ces requêtes, est essentiel pour harmoniser la jurisprudence entre les différents échelons de l’ordre administratif et accélérer les délais de jugement. Il s’agit d‘un comité siégeant au Conseil d’Etat et qui doit définir, pour chaque série identifiée, une méthode de traitement adaptée à celle-ci et, en particulier, de désigner une juridiction pilote, sur la position de laquelle les autres juridictions pourront ensuite s’aligner.
L’objectif du projet IA-JURADINFO est de viabiliser la détection de séries et d’accroître l’efficacité du dispositif actuel de détection des séries, en utilisant la compréhension du langage naturel. L’IA doit permettre d’analyser à intervalles réguliers l’ensemble des requêtes entrantes afin à la fois de proposer des rattachements aux séries connues et l’identification de séries nouvelles. L’IA doit donc être en mesure d’extraire des requêtes nouvelles la question de droit, l’article attaqué et les motivations associées.
Création d’un dossier patient fictif au CHU de Bordeaux pour lancer le projet d’IA malgré la crise du Covid-19 avec Sébastien Cossin, porteur de projet d’IA (AMI 2)
Développer une solution d’IA repose sur le traitement de données. Dans le cas du CHU de Bordeaux, le projet a pour objectif de développer un moteur de recherche dans les dossiers patients. Dans le contexte de la crise sanitaire et du confinement, l’équipe de prestataires est dans l’impossibilité d’accéder aux donnée, constituées des 1,5 million de dossiers patients. Retour avec Sébastien Cossin, assistant hospitalier universitaire dans le pôle de santé publique du CHU de Bordeaux, porteur du projet IA sélectionné par l’appel à manifestation d’intérêt IA 2.
“Avec mon collègue clinicien Mathieu Lambert, je fais partie de l’équipe porteur du projet IA au CHU de Bordeaux. Mon rôle est à l’interface entre la technique et le métier : je traduis les besoins de l’équipe métier d’un point de vue technique, et vice-versa. Nous avons lancé le projet lorsque la crise sanitaire a commencé. L’activité de tous les services du CHU a été complètement réorganisée pour accueillir les patients touchés par le Covid-19. Dans ce contexte hospitalier de crise, nos interlocuteurs cliniciens ne sont pas disponibles. Par exemple, le service hygiène, très intéressé par le projet, est actuellement entièrement consacré à la crise sanitaire.
Dans ce contexte, nous nous concentrons sur la partie technique pour que le prestataire puisse avancer : la base de connaissances que nous visons par exemple est construite en s’appuyant sur les métadonnées du CHU (terminologies pour coder les maladies, médicaments, libellés des documents et des examens biologiques etc.), que nous avons pu partager. D’autres référentiels en open data ou papiers médicaux ont aussi pu être utilisés.
Pour créer l’algorithme d’extraction d’entités, de relation et de réconciliation sur les 1.5 million de dossiers patients existants, c’est autre chose : initialement, pour les traitements nécessitant d’accéder à ces dossiers, le caractère sensible des données médicales imposait leur traitement en local, sur un poste fourni par le CHU Bordeaux.
Dans l’impossibilité d’accéder à ces données pour le prestataire pendant le confinement, nous avons alors créé un dossier patient fictif : en fait, le moteur de recherche va s’intéresser aux données d’un seul patient à la fois. Chacun de ces dossiers est unique et différent mais contient la même structure. Générer un dossier patient fictif a permis au prestataire de voir à la fois comment les données sont rattachées aux métadonnées du CHU et quels types de données se trouvent dans le dossier patient : données structurées avec des codes, non structurées avec du texte, et semi-structurées avec des questions-réponses.
Ainsi, avec l’ensemble des métadonnées partagées et des données patient fictives, le prestataire va pouvoir développer les premiers algorithmes et nous pourrons plus tard déployer le code développé à partir des données fictives sur les vraies données à l’hôpital.”
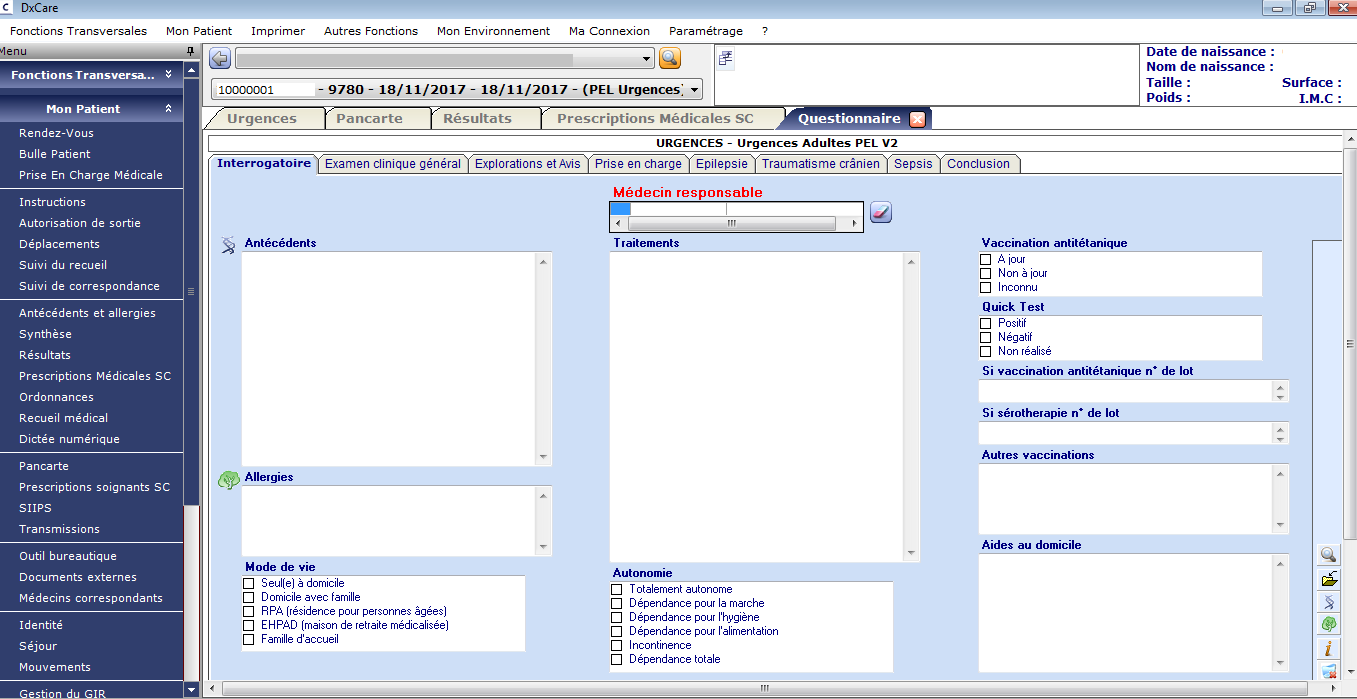
“Le dossier patient informatisé, DPI, contient l'ensemble des données d'un patient passé à l’hôpital : comptes rendus d’hospitalisation ou de consultation, questionnaire de spécialité (ici celui utilité par les urgentistes), prescriptions médicamenteuses, résultats biologiques … Les données sont stockées dans différentes applications et centralisées dans un entrepôt de données. Les données sont à la fois non structurées (données textuelles d’un compte-rendu), semi-structurées (question – réponse d’un formulaire) et structurées (code dans un référentiel). Un dossier patient synthétique issu de l’entrepôt de données permet d’expliquer la structure, le format de stockage et le contenu des DPI à l’hôpital”, explique Sébastien.
Quelques infos clés sur le projet IA du CHU de Bordeaux
En juillet dernier, le projet a été sélectionné avec 14 autres projets dans le cadre de l’Appel à Manifestation d’Intérêt (AMI) 2 pour bénéficier de l’accompagnement du Lab IA et de la DITP. Le CHU de Bordeaux porte une politique numérique ambitieuse dont l’une des réalisations principales est la création d’un entrepôt de données rassemblant l’ensemble des données de soin d’1.5 million de patients, qui pourront être utilisées à des fins de pilotage, de soins et de recherche, dans le strict respect de la réglementation. Jusqu’à 60% du temps médecin peut être destiné à la recherche d’information, selon les services.
L’utilisation de l’IA devrait permettre de :
- Disposer d’un moteur de recherche intelligent pour faciliter la recherche de concept médicaux ou entités médicales ;
- Développer (ou lier ce moteur avec) un outil type “ligne de vie” ou “timeline” pour visualiser rapidement l’historique patient.
L’outil serait en premier lieu destiné aux médecins, aux attachés de recherche clinique, et aux unités de vigilance.
Projets AMI 2 : Prochain atelier en ligne
Initialement prévu le 2 avril pour les porteurs de projets sélectionnés par l’AMI 2, l’atelier #2 se tiendra en ligne en juin : ce sera l’opportunité d’expérimenter un nouveau format ! Nous vous tiendrons informés dès que possible.